Google Cloud Platform Deployment
Production GKE deployment with VertexAI Gemini integration and comprehensive GCP services
Intermediate
2 - 4 hr
- GCP account with billing enabled (see below for setup)
- gcloud CLI installed and configured
- Pulumi installed locally
- kubectl command-line tool
- Python 3.11+ for CLI tools
- Basic command-line and Kubernetes familiarity
Deploy a production-ready TrustGraph environment on Google Kubernetes Engine with VertexAI Gemini integration using Infrastructure as Code.
Overview
This guide walks you through deploying TrustGraph on Google Cloud Platform’s Kubernetes Engine (GKE) using Pulumi (Infrastructure as Code). The deployment automatically provisions a production-ready Kubernetes cluster integrated with Google’s VertexAI services.
Pulumi is an open-source Infrastructure as Code tool that uses general-purpose programming languages (TypeScript/JavaScript in this case) to define cloud infrastructure. Unlike manual deployments, Pulumi provides:
- Reproducible, version-controlled infrastructure
- Testable and retryable deployments
- Automatic resource dependency management
- Simple rollback capabilities
Once deployed, you’ll have a complete TrustGraph stack running on GCP infrastructure with:
- Google Kubernetes Engine (GKE) cluster (2-node pool, configurable)
- VertexAI Gemini Flash 1.5 integration
- Complete monitoring with Grafana and Prometheus
- Web workbench for document processing and Graph RAG
- Secure secrets management
Why Google Cloud Platform for TrustGraph?
GCP offers unique advantages for AI-focused organizations:
- VertexAI Integration: Native access to Google’s Gemini models for state-of-the-art LLM capabilities
- ML/AI Optimization: Purpose-built infrastructure for machine learning workloads
- Global Infrastructure: Deploy across 40+ regions worldwide with Google’s network
- Sustainability: Carbon-neutral operations with renewable energy commitment
- Free Tier & Credits: $300 in free credits for new users to get started
Ideal for organizations requiring cutting-edge AI capabilities and ML/AI-optimized infrastructure.
Getting ready
GCP Account
You’ll need a GCP account with billing enabled. If you don’t have one:
- Sign up at https://cloud.google.com/
- Complete account verification
- Enable billing for your project
- New users receive $300 in free credits
Create a GCP Project
Create a dedicated project for TrustGraph:
- Navigate to the GCP Console
- Click on the project dropdown at the top
- Click New Project
- Enter a project name (e.g.,
trustgraph-prod) - Note the Project ID - you’ll need this later
Enable Required APIs
Enable the necessary GCP APIs for your project:
gcloud services enable container.googleapis.com
gcloud services enable compute.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable iam.googleapis.com
Install gcloud CLI
Install the Google Cloud CLI:
Linux
curl https://sdk.cloud.google.com | bash
exec -l $SHELL
gcloud init
MacOS
brew install --cask google-cloud-sdk
gcloud init
Windows
Download the installer from cloud.google.com/sdk/docs/install
Verify installation:
gcloud version
Configure gcloud Authentication
Authenticate with your GCP account:
gcloud auth login
gcloud auth application-default login
Set your default project:
gcloud config set project YOUR_PROJECT_ID
Python
You need Python 3.11 or later installed for the TrustGraph CLI tools.
Check your Python version
python3 --version
If you need to install or upgrade Python, visit python.org.
Pulumi
Install Pulumi on your local machine:
Linux
curl -fsSL https://get.pulumi.com | sh
MacOS
brew install pulumi/tap/pulumi
Windows
Download the installer from pulumi.com.
Verify installation:
pulumi version
Full installation details are at pulumi.com.
kubectl
Install kubectl to manage your Kubernetes cluster:
- Linux: Install kubectl on Linux
- MacOS:
brew install kubectl - Windows: Install kubectl on Windows
Verify installation:
kubectl version --client
Node.js
The Pulumi deployment code uses TypeScript/JavaScript, so you’ll need Node.js installed:
- Download: nodejs.org (LTS version recommended)
- Linux:
sudo apt install nodejs npm(Ubuntu/Debian) orsudo dnf install nodejs(Fedora) - MacOS:
brew install node
Verify installation:
node --version
npm --version
VertexAI Access
The deployment uses Google’s VertexAI with Gemini Flash 1.5 as the default model. VertexAI is automatically available in GCP projects with billing enabled.
Available Gemini models include:
gemini-1.5-flash(fast, cost-effective)gemini-1.5-pro(advanced reasoning)gemini-1.0-pro(production-ready)
Prepare the deployment
Get the Pulumi code
Clone the TrustGraph GCP Pulumi repository:
git clone https://github.com/trustgraph-ai/pulumi-trustgraph-gke.git
cd pulumi-trustgraph-gke/pulumi
Install dependencies
Install the Node.js dependencies for the Pulumi project:
npm install
Configure GCP Project
Set your GCP project ID for Pulumi:
pulumi config set gcp:project YOUR_PROJECT_ID
Configure Pulumi state
You need to tell Pulumi which state to use. You can store this in an S3 bucket, but for experimentation, you can just use local state:
pulumi login --local
When storing secrets in the Pulumi state, pulumi uses a secret passphrase to encrypt secrets. When using Pulumi in a production or shared environment you would have to evaluate the security arrangements around secrets.
We’re just going to set this to the empty string, assuming that no encryption is fine for a development deploy.
export PULUMI_CONFIG_PASSPHRASE=
Create a Pulumi stack
Initialize a new Pulumi stack for your deployment:
pulumi stack init dev
You can use any name instead of dev - this helps you manage multiple deployments (dev, staging, prod, etc.).
Configure the stack
Apply settings for region, zone, and cluster configuration:
pulumi config set gcp:region us-central1
pulumi config set gcp:zone us-central1-a
pulumi config set clusterName trustgraph-gke
pulumi config set nodeCount 2
Available regions include:
us-central1(Iowa, USA)us-east1(South Carolina, USA)europe-west1(Belgium)europe-west4(Netherlands)asia-southeast1(Singapore)australia-southeast1(Sydney)
Refer to GCP Regions for a complete list.
Configure VertexAI
Set the VertexAI model and location:
pulumi config set vertexaiModel gemini-1.5-flash
pulumi config set vertexaiLocation us-central1
Refer to the repository’s README for additional configuration options.
Deploy with Pulumi
Preview the deployment
Before deploying, preview what Pulumi will create:
pulumi preview
This shows all the resources that will be created:
- GKE Kubernetes cluster
- Node pool with specified machine types
- VPC network and subnets
- Service accounts with VertexAI permissions
- IAM roles and bindings
- Kubernetes secrets for GCP credentials
- TrustGraph deployments, services, and config maps
Review the output to ensure everything looks correct.
Deploy the infrastructure
Deploy the complete TrustGraph stack:
pulumi up
Pulumi will ask for confirmation before proceeding. Type yes to continue.
The deployment typically takes 10 - 15 minutes and progresses through these stages:
- Creating GKE cluster (6-8 minutes)
- Provisions GKE cluster
- Creates node pool
- Configures VPC networking
- Configuring service accounts (1-2 minutes)
- Creates service account
- Sets up VertexAI permissions
- Creates Kubernetes secrets
- Deploying TrustGraph (4-6 minutes)
- Applies Kubernetes manifests
- Deploys all TrustGraph services
- Starts pods and initializes services
You’ll see output showing the creation progress of all resources.
Configure and verify kubectl access
After deployment completes, configure kubectl to access your GKE cluster:
gcloud container clusters get-credentials trustgraph-gke --zone us-central1-a
Verify access:
kubectl get nodes
You should see your GKE nodes listed as Ready.
Check pod status
Verify that all pods are running:
kubectl -n trustgraph get pods
You should see output similar to this (pod names will have different random suffixes):
NAME READY STATUS RESTARTS AGE
agent-manager-74fbb8b64-nzlwb 1/1 Running 0 5m
api-gateway-b6848c6bb-nqtdm 1/1 Running 0 5m
cassandra-6765fff974-pbh65 1/1 Running 0 5m
pulsar-d85499879-x92qv 1/1 Running 0 5m
text-completion-58ccf95586-6gkff 1/1 Running 0 5m
workbench-ui-5fc6d59899-8rczf 1/1 Running 0 5m
...
All pods should show Running status. Some init pods (names ending in -init) may fail or be shown Completed status - this is normal, their job is to initialise cluster resources and then exit.
Access services via port-forwarding
Since the Kubernetes cluster is running on Scaleway, you’ll need to set up port-forwarding to access TrustGraph services from your local machine.
Open three separate terminal windows and run these commands (keep them running):
Terminal 1 - API Gateway:
export KUBECONFIG=$(pwd)/kubeconfig.yaml
kubectl -n trustgraph port-forward svc/api-gateway 8088:8088
Terminal 2 - Workbench UI:
export KUBECONFIG=$(pwd)/kubeconfig.yaml
kubectl -n trustgraph port-forward svc/workbench-ui 8888:8888
Terminal 3 - Grafana:
export KUBECONFIG=$(pwd)/kubeconfig.yaml
kubectl -n trustgraph port-forward svc/grafana 3000:3000
With these port-forwards running, you can access:
- TrustGraph API: http://localhost:8088
- Web Workbench: http://localhost:8888
- Grafana Monitoring: http://localhost:3000
Keep these terminal windows open while you’re working with TrustGraph. If you close them, you’ll lose access to the services.
Install CLI tools
Now install the TrustGraph command-line tools. These tools help you interact with TrustGraph, load documents, and verify the system.
Create a Python virtual environment and install the CLI:
python3 -m venv env
source env/bin/activate # On Windows: env\Scripts\activate
pip install trustgraph-cli
Set the IAM bootstrap token so that CLI tools can authenticate:
export TRUSTGRAPH_TOKEN=$(pulumi stack output iamToken --show-secrets)
Grafana access
Login to Grafana with username admin and the password from:
pulumi stack output grafanaPassword --show-secrets
Startup period
It can take 2-3 minutes for all services to stabilize after deployment. Services like Pulsar and Cassandra need time to initialize properly.
Verify system health
tg-verify-system-status
If everything is working, the output looks something like this:
============================================================
TrustGraph System Status Verification
============================================================
Phase 1: Infrastructure
------------------------------------------------------------
[00:00] ⏳ Checking Pulsar...
[00:03] ⏳ Checking Pulsar... (attempt 2)
[00:03] ✓ Pulsar: Pulsar healthy (0 cluster(s))
[00:03] ⏳ Checking API Gateway...
[00:03] ✓ API Gateway: API Gateway is responding
Phase 2: Core Services
------------------------------------------------------------
[00:03] ⏳ Checking Processors...
[00:03] ✓ Processors: Found 34 processors (≥ 15)
[00:03] ⏳ Checking Flow Classes...
[00:06] ⏳ Checking Flow Classes... (attempt 2)
[00:09] ⏳ Checking Flow Classes... (attempt 3)
[00:22] ⏳ Checking Flow Classes... (attempt 4)
[00:35] ⏳ Checking Flow Classes... (attempt 5)
[00:38] ⏳ Checking Flow Classes... (attempt 6)
[00:38] ✓ Flow Classes: Found 9 flow class(es)
[00:38] ⏳ Checking Flows...
[00:38] ✓ Flows: Flow manager responding (1 flow(s))
[00:38] ⏳ Checking Prompts...
[00:38] ✓ Prompts: Found 16 prompt(s)
Phase 3: Data Services
------------------------------------------------------------
[00:38] ⏳ Checking Library...
[00:38] ✓ Library: Library responding (0 document(s))
Phase 4: User Interface
------------------------------------------------------------
[00:38] ⏳ Checking Workbench UI...
[00:38] ✓ Workbench UI: Workbench UI is responding
============================================================
Summary
============================================================
Checks passed: 8/8
Checks failed: 0/8
Total time: 00:38
✓ System is healthy!
The Checks failed line is the most interesting and is hopefully zero. If you are having issues, look at the troubleshooting section later.
If everything appears to be working, the following parts of the deployment guide are a whistle-stop tour through various parts of the system.
Test LLM access
Test that VertexAI Gemini integration is working by invoking the LLM through the gateway:
tg-invoke-llm 'Be helpful' 'What is 2 + 2?'
You should see output like:
2 + 2 = 4
This confirms that TrustGraph can successfully communicate with Google’s VertexAI service.
Load sample documents
Load a small set of sample documents into the library for testing:
tg-load-sample-documents
This downloads documents from the internet and caches them locally. The download can take a little time to run.
Workbench
TrustGraph includes a web interface for document processing and Graph RAG.
Access the TrustGraph workbench at http://localhost:8888 (requires port-forwarding to be running).
You will see a login page. Select the API Key tab and enter the IAM bootstrap token retrieved earlier, then click Connect.
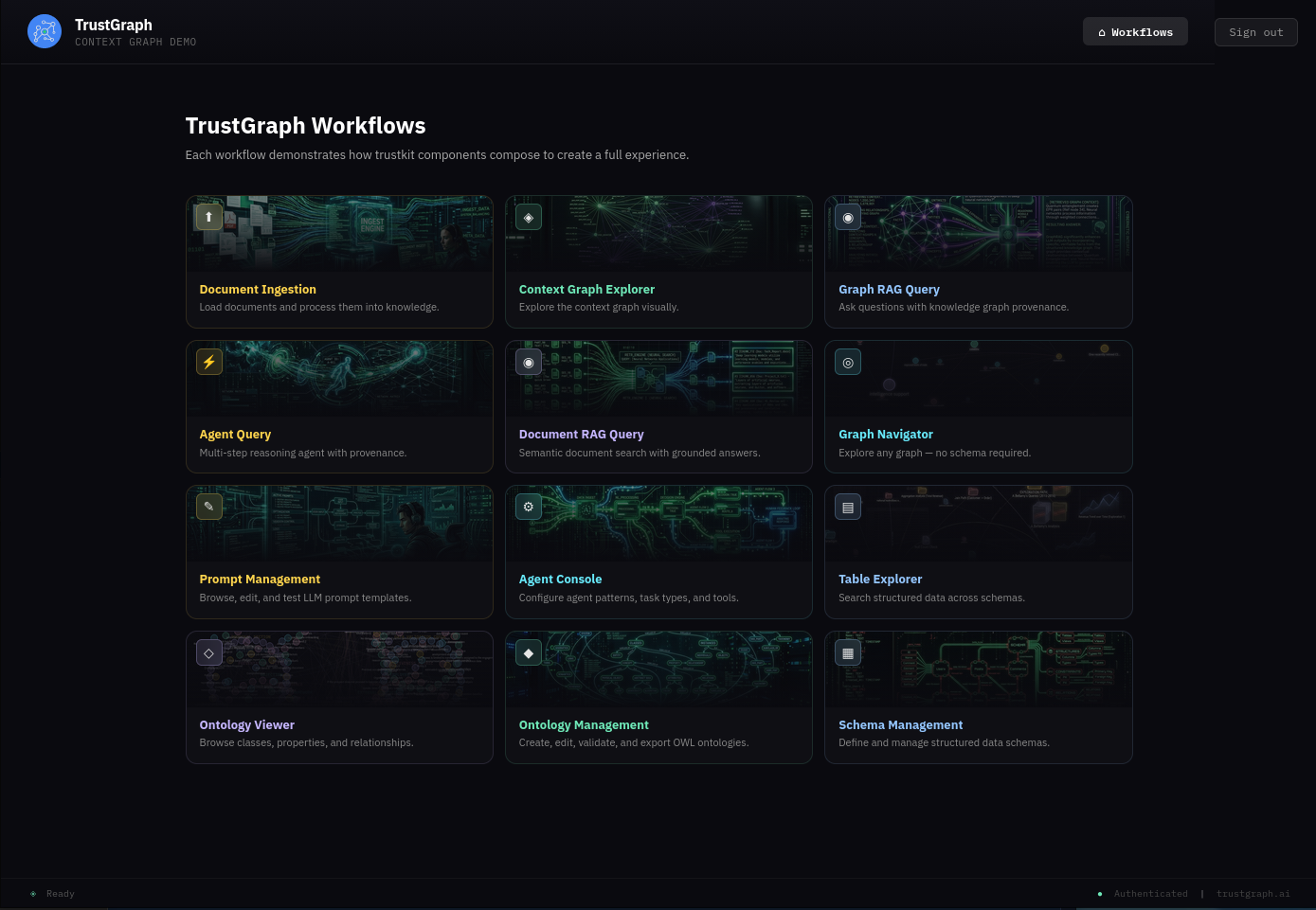
After logging in, you should see the Workflows page showing the available workflows. At the top right of the screen is a Workflows button which brings you back to this page from anywhere in the workbench.
The guide will return to the workbench to load a document.
Monitoring dashboard
Access Grafana monitoring at http://localhost:3000 (requires port-forwarding to be running).
Default credentials:
- Username:
admin - Password:
admin
All TrustGraph components collect metrics using Prometheus and make these available using this Grafana workbench. The Grafana deployment is configured with 2 dashboards:
- Overview metrics dashboard: Shows processing metrics
- Logs dashboard: Shows collated TrustGraph container logs
For a newly launched system, the metrics won’t be particularly interesting yet.
Check the LLM is working
If the tg-invoke-llm command worked earlier, you can skip this section. Otherwise, this is a quick way to verify LLM access through the workbench while introducing the prompt management workflow.
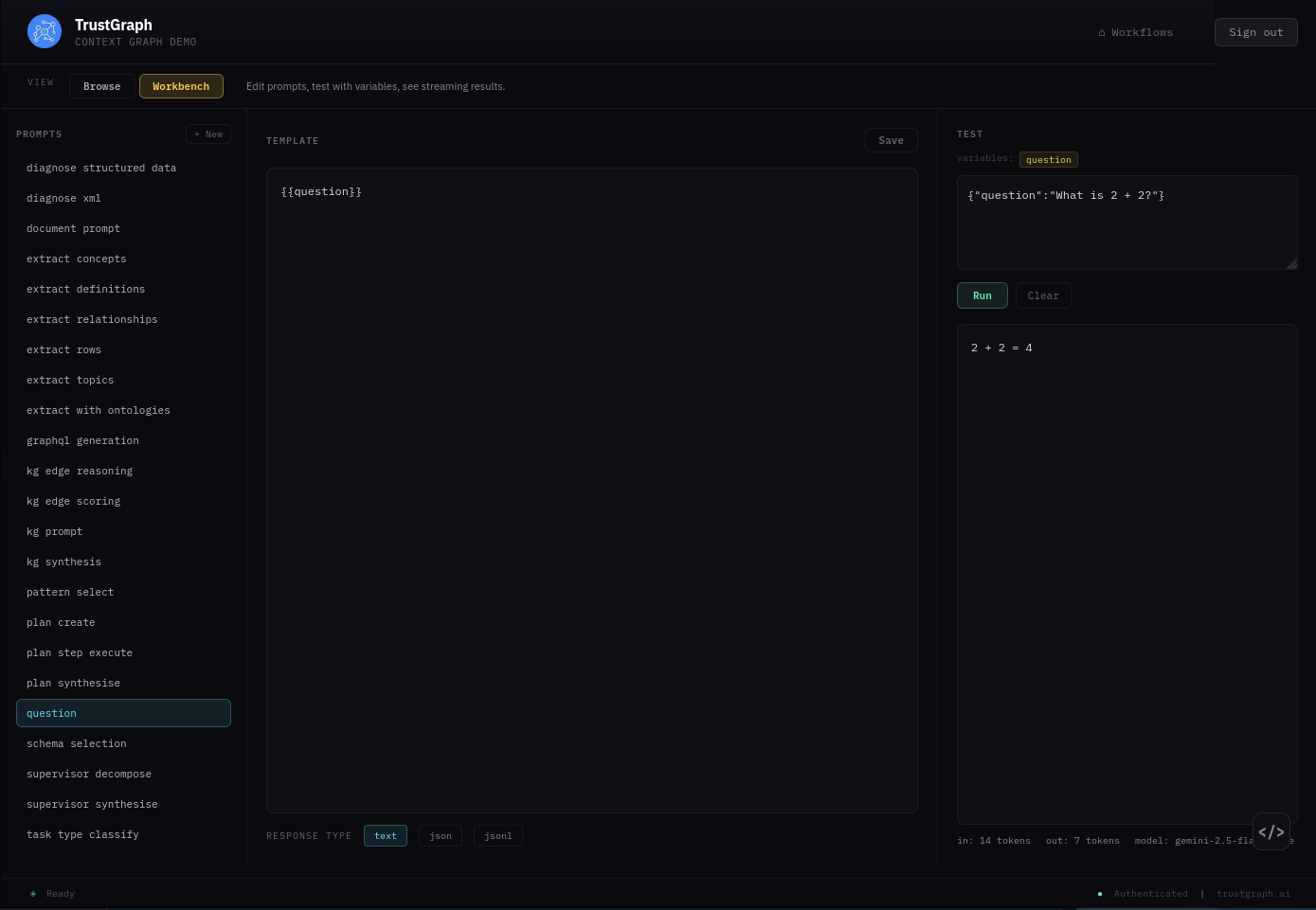
From the Workflows page, select Prompt Management. This screen is where all the prompt templates live. You can edit existing templates and construct your own.
To run a simple test, find the question prompt in the list on the left and select it. The template is straightforward — just {{question}} — which means the question variable is fed directly to the LLM.
On the right-hand side, change the TEST box from {} to:
{"question": "What is 2 + 2?"}
Click Run. You should see the answer to your question appear below.
If you want to experiment with prompts, try adding “Please provide a detailed explanation” to the prompt template, click Save, and run the test again to see a different response.
If LLM interactions are not working, check the Grafana logs dashboard for errors in the text-completion service.
Working with a document
Load a document
Back on the Workflows page, select Document Ingestion. If the sample documents were loaded earlier, you should see 7 documents listed.
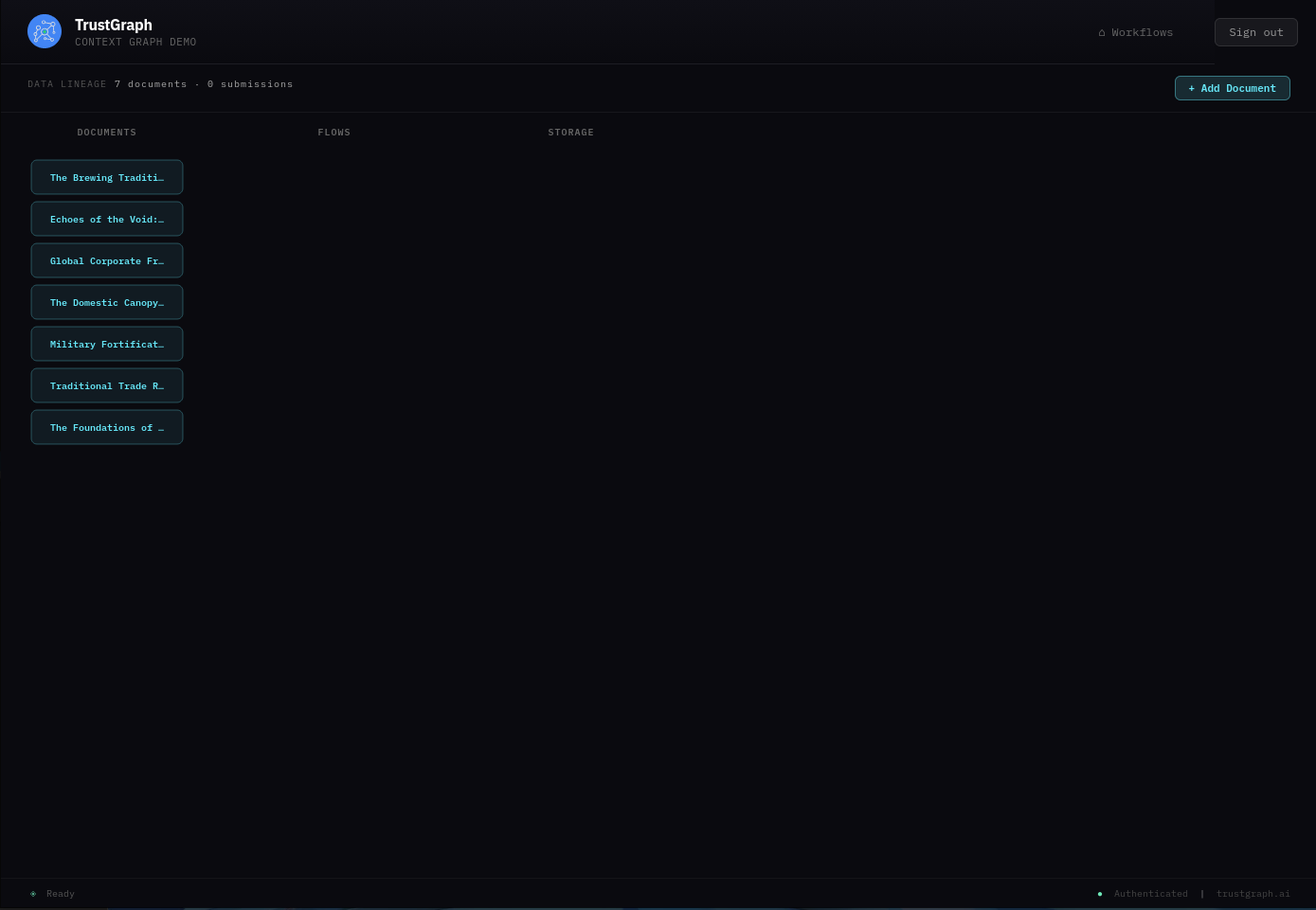
Find Echoes of the Void and select it. You should see document information including a description, tags, and upload date.

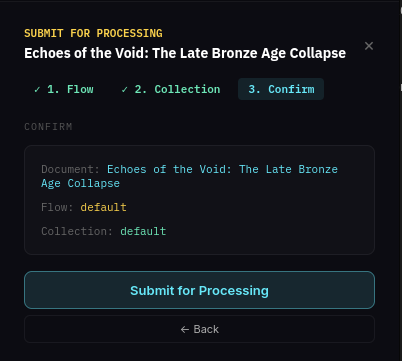
Click Submit for Processing. The submission wizard has three steps:
1. Select a flow — choose the default flow which already exists.

2. Select a collection — use the existing default collection.

3. Confirm — review the details and click Submit for Processing.
If submission is successful, the main screen should show the document’s processing pipeline — the document flowing through the selected flow into the storage backends.
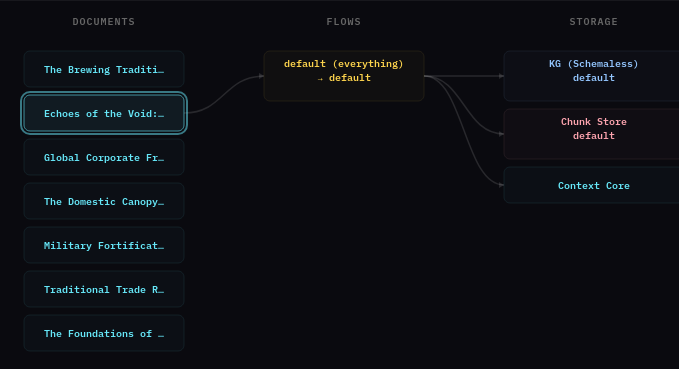
This is a short document and should process quickly, depending on the LLM resource you are using.
There is also an + Add Document button in the top right which can be used to submit your own documents.
Look at knowledge graph
From the Workflows page, select Graph Explorer. This shows what’s in the knowledge graph with tools for viewing and searching.
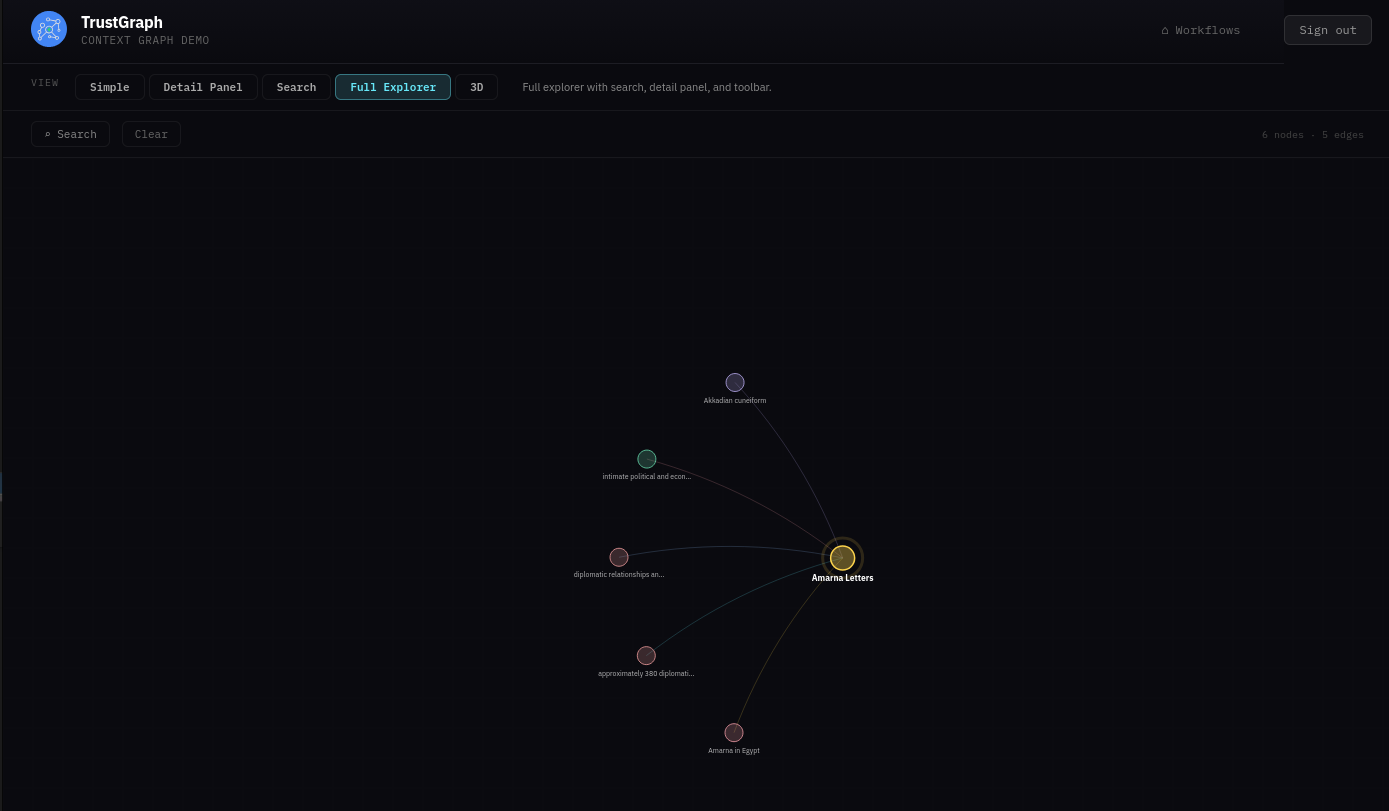
The graph can be easier to see in 3D — click the 3D button above the graph view.
If you click a node, it will be highlighted along with its related edges. A side panel also appears showing node properties and highlighted links that allow you to navigate to related nodes.
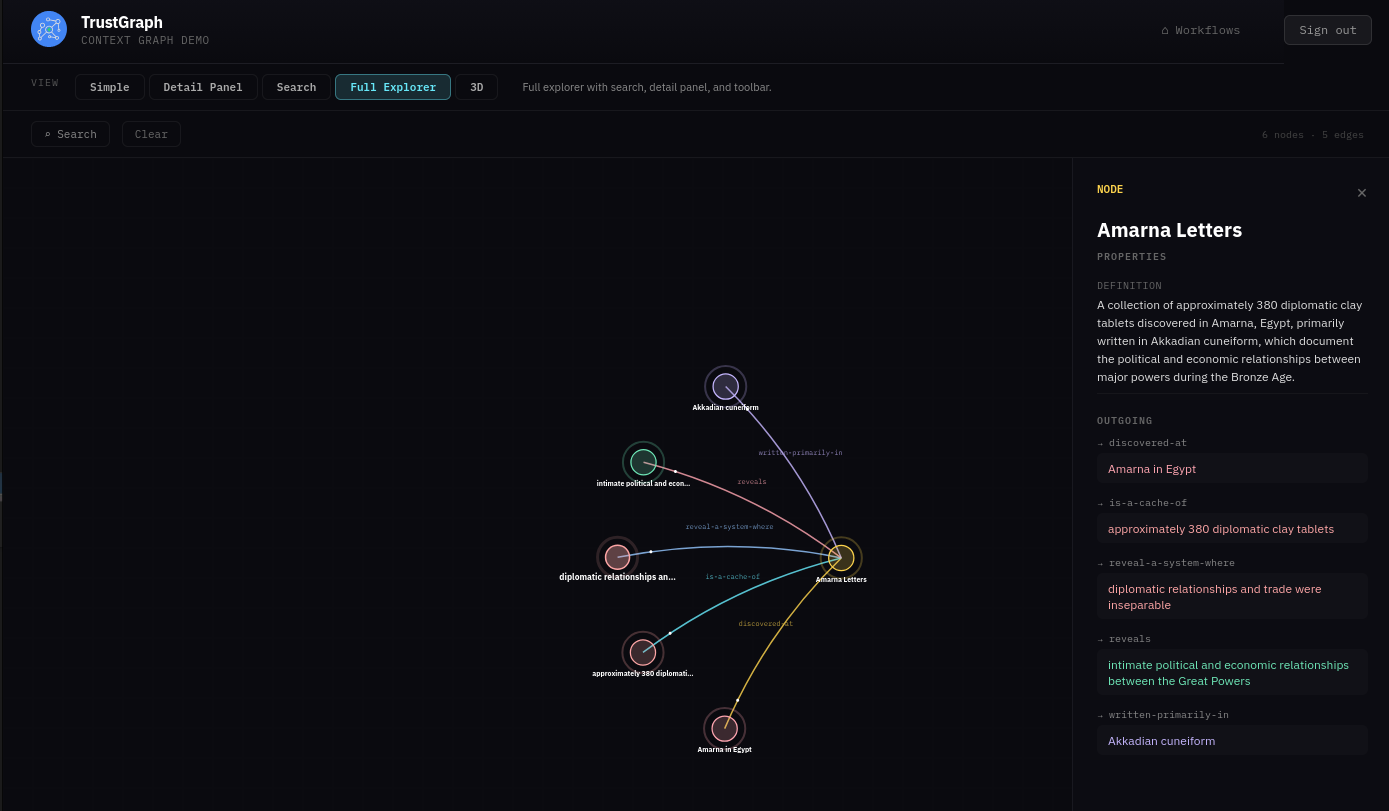
On the top left is a Search button which opens a search dialog. You can enter text for a similarity search against nodes in the graph. Matching nodes are listed and can be selected, which adds them to the graph along with their neighbours.
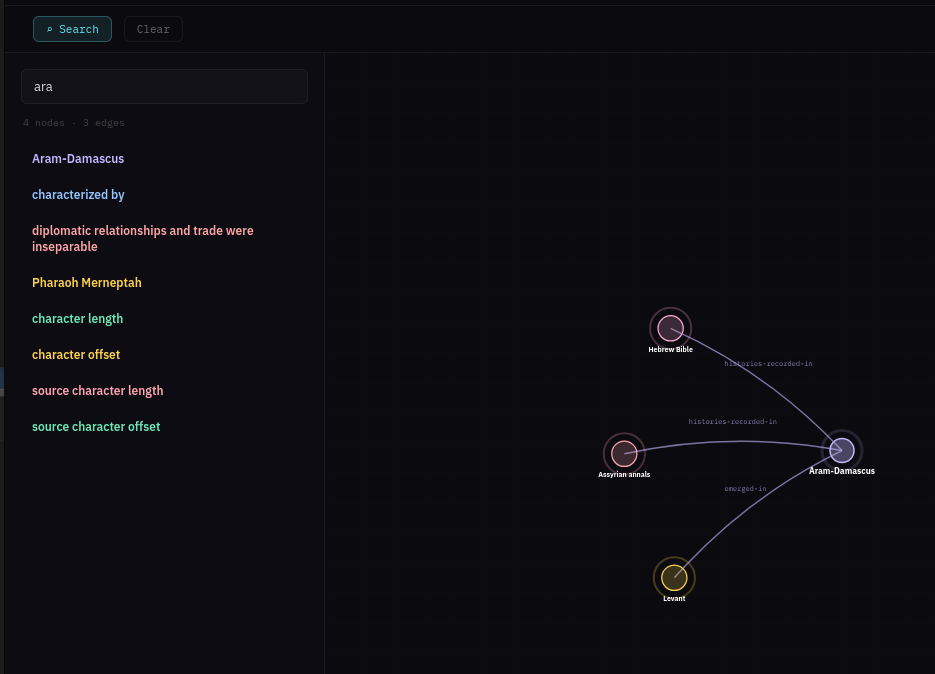
There is also a Clear button which resets the graph back to an empty state.
Query with Graph RAG
From the Workflows page, select Graph RAG Query. This console is more than your average chatbot — it has full Explainable AI enabled. This helps to understand and diagnose retrieval, but is not intended as an end-user experience.
Enter a query such as “What was the cause of the Bronze Age Collapse?” and after a short while you should see a response.
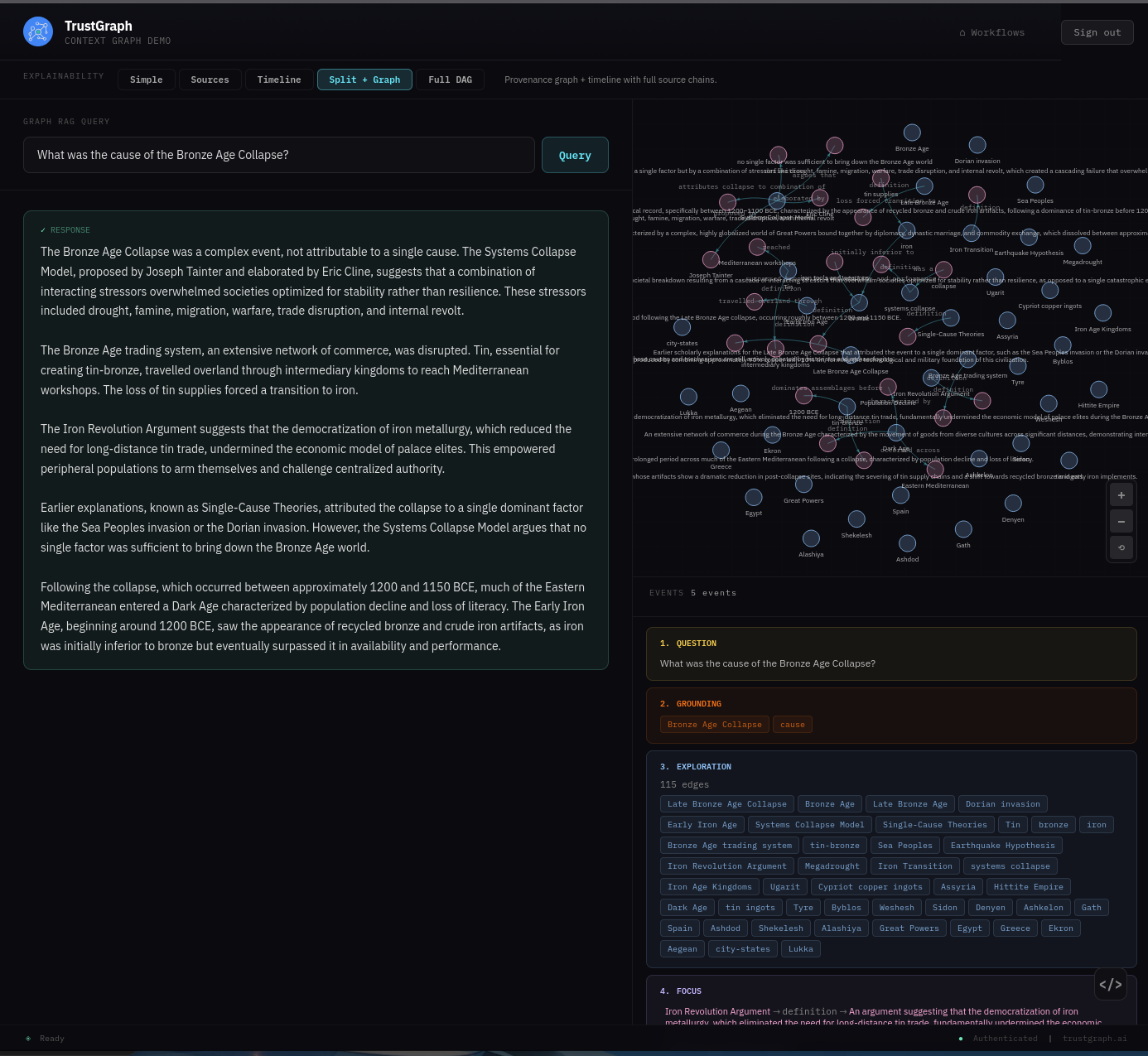
There is a lot to see here if you are interested. The bottom right part of the screen shows the various explainability events, starting from the question:
- Grounding — where retrieval selects key concepts for discovery
- Exploration — where graph nodes are selected for analytics
- Focus — where the system decides on a core set of graph edges to resolve the question
- Synthesis — where this is processed to provide an answer
On the left-hand side you see the actual answer to the query. The Focus event may be of particular interest as you can trace graph edges all the way back to the source documents. For example, the graph edge (Systems Collapse Model → proposed by → Joseph Tainter) has a link to source below which, when followed, shows the original source text.

Troubleshooting
Deployment Issues
Pulumi deployment fails
Diagnosis:
Check the Pulumi error output for specific failure messages. Common issues include:
# View detailed error information
pulumi stack --show-urns
pulumi logs
Resolution:
- Authentication errors: Verify
gcloud auth application-default loginwas run and your project ID is correct - API not enabled: Ensure all required GCP APIs are enabled (see “Enable Required APIs” section)
- Quota limits: Check your GCP project hasn’t hit resource quotas (GKE clusters, CPUs, IP addresses)
- Billing not enabled: Verify billing is enabled for your GCP project
- Permissions: Ensure your account has Owner or Editor role on the project
Pods stuck in Pending state
Diagnosis:
kubectl -n trustgraph get pods | grep Pending
kubectl -n trustgraph describe pod <pod-name>
Look for scheduling failures or resource constraints in the describe output.
Resolution:
- Insufficient resources: Increase node count or machine type in your Pulumi configuration
- PersistentVolume issues: Check PV/PVC status with
kubectl -n trustgraph get pv,pvc - Node issues: Check node status with
kubectl get nodes - Resource quotas: Verify your GCP project hasn’t hit CPU or memory quotas
VertexAI integration not working
Diagnosis:
Test LLM connectivity:
tg-invoke-llm '' 'What is 2+2'
A timeout or error indicates VertexAI configuration issues. Check the text-completion pod logs:
kubectl -n trustgraph logs -l app=text-completion
Resolution:
- Verify VertexAI API is enabled:
gcloud services list --enabled | grep aiplatform - Check service account has VertexAI permissions:
gcloud projects get-iam-policy YOUR_PROJECT_ID - Ensure the Gemini model is available in your selected region
- Review Pulumi outputs to confirm VertexAI configuration:
pulumi stack output - Verify billing is enabled (VertexAI requires active billing)
Port-forwarding connection issues
Diagnosis:
Port-forward commands fail or connections time out.
Resolution:
- Verify kubectl is configured:
kubectl config current-context - Check that the target service exists:
kubectl -n trustgraph get svc - Ensure no other process is using the port (e.g., port 8088, 8888, or 3000)
- Try restarting the port-forward with verbose logging:
kubectl port-forward -v=6 ... - Check GKE cluster connectivity:
gcloud container clusters describe trustgraph-gke --zone us-central1-a
Service Failure
Pods in CrashLoopBackOff
Diagnosis:
# Find crashing pods
kubectl -n trustgraph get pods | grep CrashLoopBackOff
# View logs from crashed container
kubectl -n trustgraph logs <pod-name> --previous
Resolution:
Check the logs to identify why the container is crashing. Common causes:
- Application errors (configuration issues)
- Missing dependencies (ensure all required services are running)
- Incorrect secrets or environment variables
- Resource limits too low
- GCP credentials not properly configured
Service not responding
Diagnosis:
Check service and pod status:
kubectl -n trustgraph get svc
kubectl -n trustgraph get pods
kubectl -n trustgraph logs <pod-name>
Resolution:
- Verify the pod is running and ready
- Check pod logs for errors
- Ensure port-forwarding is active for the service
- Use
tg-verify-system-statusto check overall system health - Check GKE cluster health:
gcloud container clusters describe trustgraph-gke --zone us-central1-a
GCP-Specific Issues
GKE cluster creation fails
Diagnosis:
Check GCP quota and permissions:
gcloud compute project-info describe --project=YOUR_PROJECT_ID
Resolution:
- Request quota increases if needed via GCP Console
- Verify your account has
roles/container.adminpermission - Check if the zone has available capacity
- Try a different zone or region
VertexAI quota exceeded
Diagnosis:
Error messages about VertexAI quota or rate limits.
Resolution:
- Check VertexAI quotas in GCP Console under “IAM & Admin” → “Quotas”
- Request quota increases if needed
- Switch to a different Gemini model with higher quotas
- Implement rate limiting in your application
Shutting down
Clean shutdown
When you’re finished with your TrustGraph deployment, clean up all resources:
pulumi destroy
Pulumi will show you all the resources that will be deleted and ask for confirmation. Type yes to proceed.
The destruction process typically takes 8-12 minutes and removes:
- All TrustGraph Kubernetes resources
- The GKE cluster
- Node pools
- Service accounts and IAM bindings
- VPC network resources (if created)
- All associated storage
Cost Warning: GCP charges for running GKE clusters and node instances. Make sure to destroy your deployment when you’re not using it to avoid unnecessary costs. GKE charges include cluster management fees plus compute costs.
Verify cleanup
After pulumi destroy completes, verify all resources are removed:
# Check Pulumi stack status
pulumi stack
# Verify no resources remain
pulumi stack --show-urns
# Check GCP for remaining resources
gcloud container clusters list
gcloud compute instances list
Delete the Pulumi stack
If you’re completely done with this deployment, you can remove the Pulumi stack:
pulumi stack rm dev
This removes the stack’s state but doesn’t affect any cloud resources (use pulumi destroy first).
Cost Optimization
Monitor Costs
Keep track of your GCP spending:
- Navigate to Billing in GCP Console
- View cost breakdown by service
- Set up budget alerts
Cost-Saving Tips
- Preemptible Nodes: Use preemptible VMs for non-production workloads (60-90% cheaper)
- Autoscaling: Configure cluster autoscaling to scale down during idle periods
- Resource Requests: Set appropriate CPU/memory requests to avoid over-provisioning
- Committed Use Discounts: For long-term deployments, purchase committed use contracts
- Regional vs Zonal: Use zonal clusters instead of regional for lower costs (less HA)
Example cost estimates (us-central1):
- Cluster management fee: $0.10/hour (~$73/month)
- 2 x n1-standard-2 nodes: ~$100/month
- VertexAI API calls: Pay per use (varies by model and usage)
- Total estimated: ~$180-250/month for basic deployment
Next Steps
Now that you have TrustGraph running on GCP:
- Guides: See Guides for things you can do with your running TrustGraph
- Scale the cluster: Configure GKE autoscaling or increase node pool size
- Production hardening: Set up Cloud Armor, Cloud NAT, and private GKE cluster
- Integrate GCP services: Connect to Cloud Storage, BigQuery, or Cloud SQL
- CI/CD: Set up Cloud Build for automated deployments
- Monitoring: Integrate with Cloud Monitoring and Cloud Logging
- Multi-region: Deploy across multiple GCP regions for high availability
- Advanced VertexAI: Explore other Gemini models or fine-tuning options
Additional Resources
- TrustGraph GCP Pulumi Repository - Full source code and configuration
- GKE Best Practices - Google’s recommendations
- VertexAI Documentation - Learn more about Google’s AI platform
- GCP Free Tier - Information about free credits and always-free resources